Summary
In 2025, an autonomous system reached number one on HackerOne’s global leaderboard. It outperformed thousands of human ethical hackers. Google’s Big Sleep agent found the first publicly documented AI-discovered zero-day in production software. On the academic side, multi-agent architectures pairing LLM reasoning with classical planning are hitting 85% success rates on standardized pentesting benchmarks.
This is not a better scanner. These systems read code, form hypotheses about what might be vulnerable, write exploits, and try again when the first attempt doesn’t work. The shift from scripted automation to actual autonomous reasoning is real, and it happened faster than most people expected.
This post is our attempt to cut through the noise: what the architectures look like under the hood, which results actually matter, where the obvious limitations are, and what we think comes next.
Background
The bottleneck
Pentesting is slow work. A typical web app engagement means days of recon, manual probing, exploit dev, and report writing. There aren’t enough skilled pentesters to go around, and the attack surface keeps growing: APIs, microservices, cloud infrastructure, CI/CD pipelines, IoT devices.
The math doesn’t work out. Pentests happen quarterly or annually. Code ships daily. Vulnerabilities live in that gap.
Automation vs. autonomy
The previous generation of tools (Nessus, OpenVAS, Metasploit, various orchestration wrappers) handles known vulnerability signatures well enough. What they can’t do is reason about novel attack paths, chain low-severity findings into something worse, or change strategy when a target behaves unexpectedly.
Automation does the same thing faster. Autonomy reasons and acts on its own. LLMs close that gap.
LLMs as offensive reasoning engines
Large language models bring something genuinely new to offensive security. They read source code, understand app logic, form hypotheses about vulnerabilities, generate exploit payloads, and adjust when things don’t work. Hook that up to tool-use interfaces (code execution, network scanning, browser interaction) and you get agents running multi-step attack chains without much human input.
Analysis
Architecture patterns
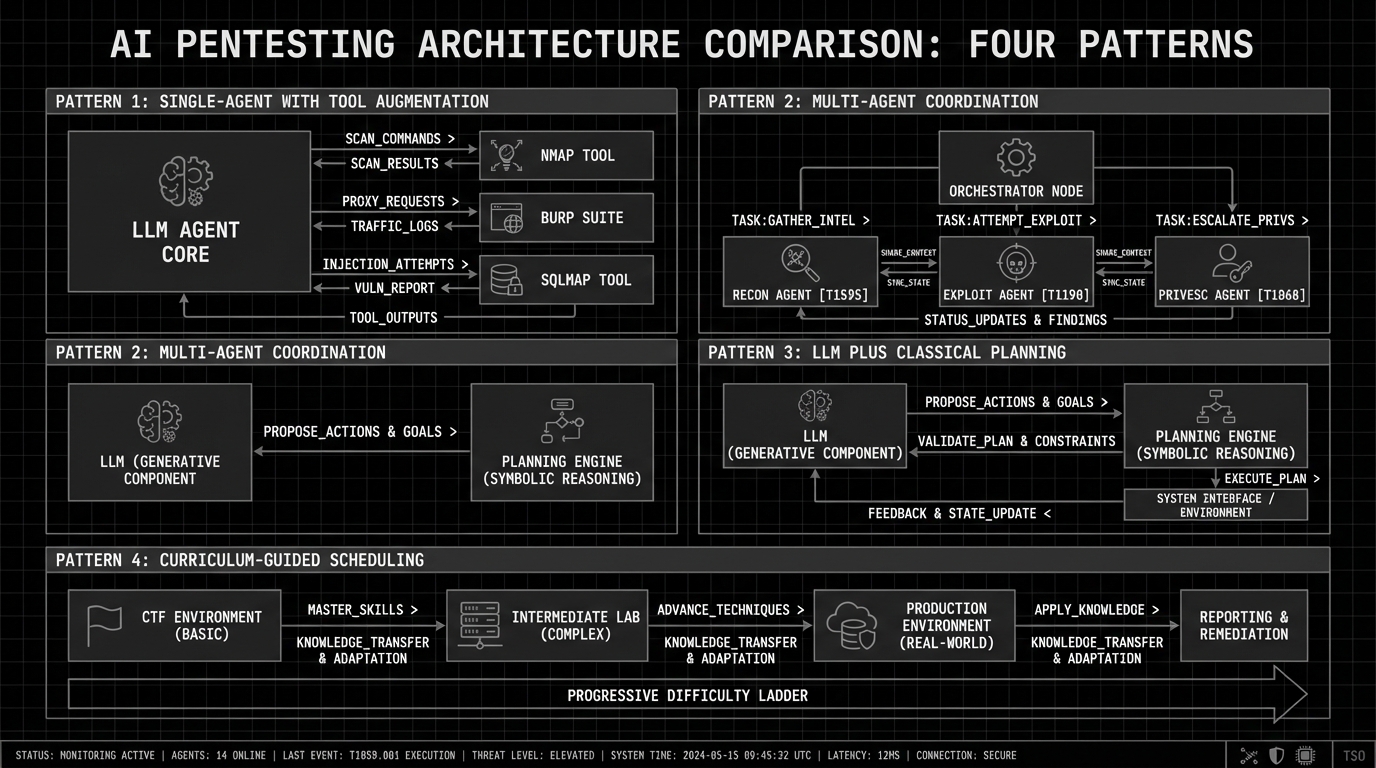
Four patterns show up across current AI pentesting systems:
Single-agent with tool augmentation. The simplest version: one LLM with access to a toolkit (Nmap, Burp Suite, sqlmap, custom scripts). It picks a tool, interprets the output, plans the next step. PentestGPT pioneered this with three modules: reasoning, task tracking, and tool execution. PentestGPT V2 hit 85% success rates (up from 61% baseline) while making 23% fewer LLM calls by structuring tool interfaces more carefully.
Multi-agent coordination. Specialized agents for recon, exploitation, and privilege escalation, all managed by an orchestrator. XBOW does this at scale with hundreds of agents, each targeting a specific attack vector. PentestAgent takes the same idea and adds RAG to maintain a knowledge base of pentesting techniques across runs.
LLM plus classical planning. The CheckMate framework pairs an LLM with a classical planning engine that handles structured attack planning, compensating for the LLM’s weakness at long-horizon reasoning. This improved benchmark success rates by over 20% while cutting time and cost by more than half.
Curriculum-guided scheduling. CurriculumPT trains agents on progressively harder tasks, the same way human pentesters build skills through CTFs before touching production systems.
Three results worth paying attention to
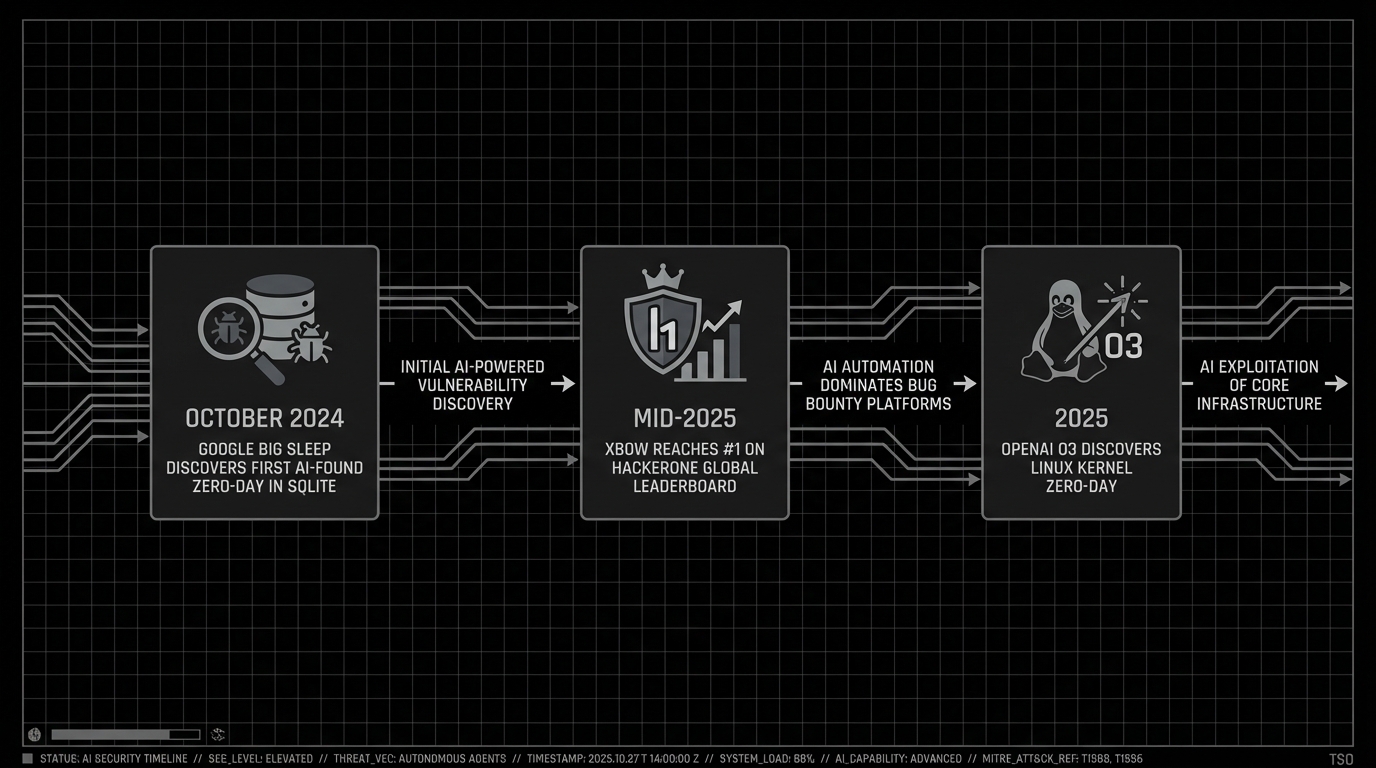
Google Big Sleep: first AI-found zero-day. In October 2024, Project Zero and DeepMind found an exploitable stack buffer underflow in SQLite’s seriesBestIndex function. The bug was a mishandled sentinel value (-1 in the iColumn field). It was reported and patched the same day, before shipping in any official release. Big Sleep works the way a human vuln researcher would: navigating codebases, generating fuzzing inputs, running them in a sandbox, debugging the results.
XBOW hits #1 on HackerOne. Mid-2025, XBOW became the first AI system to top HackerOne’s global leaderboard. Between April and June, it submitted 885 classified vulnerabilities (54 critical, 242 high, 524 medium, 65 low). Total zero-day count passed 1,400. In a benchmark, XBOW matched the output of a 20-year veteran across 104 challenges, finishing in 28 minutes what took the human 40 hours. Targets included Amazon, Disney, PayPal, and Sony. Worth noting: XBOW still requires human review before submitting reports.
OpenAI o3 finds a Linux kernel zero-day. o3 discovered CVE-2025-37899, a remote zero-day in the kernel’s SMB implementation. This showed that LLM reasoning works on low-level codebases, not just web apps.
What works today
AI pentesting agents are reliably good at web app vulnerabilities: XSS, SQL injection, SSRF, auth bypass, insecure direct object references. Multi-agent setups chain these into bigger attack paths. They’re also strong on API testing (fuzzing endpoints, finding undocumented parameters, probing authorization boundaries), and they can match known vulnerability patterns across large codebases much faster than anyone doing it manually.
Report writing is maybe the least glamorous win, but it’s real. Generating finding descriptions, impact assessments, and remediation guidance saves a lot of time. Same with recon: subdomain enumeration, port scanning, service fingerprinting.
Where humans are still irreplaceable
The kind of bugs that earn CVEs and conference talks still need human creativity. AI finds instances of known patterns but rarely discovers something genuinely new. The intuition that something “feels off” about an authentication flow, the experience to recognize a subtle race condition from a timing discrepancy, the ability to think like the developer who wrote the code and figure out what they missed: that’s still a human skill.
Red teaming engagements are where this is most obvious. A real red team op involves reading a target organization, understanding its culture, its processes, its people. Social engineering, physical access decisions, supply chain analysis, maintaining persistence across weeks without getting caught. These require judgment, adaptability, and a kind of adversarial empathy that current LLMs simply don’t have. Context windows degrade over extended operations. Planning coherence falls apart. Honeypots and active defenders confuse agents that can’t recognize deception.
Writing reliable exploits against modern binaries with ASLR, CFI, and stack canaries is still mostly a human job. Same with business logic bugs, where you need to understand the intended business workflow to spot the flaw, not just the code. The human pentester’s ability to step back and ask “what was the developer trying to do here, and where did they cut corners?” remains the thing that no model can replicate yet.
The workflow that actually works
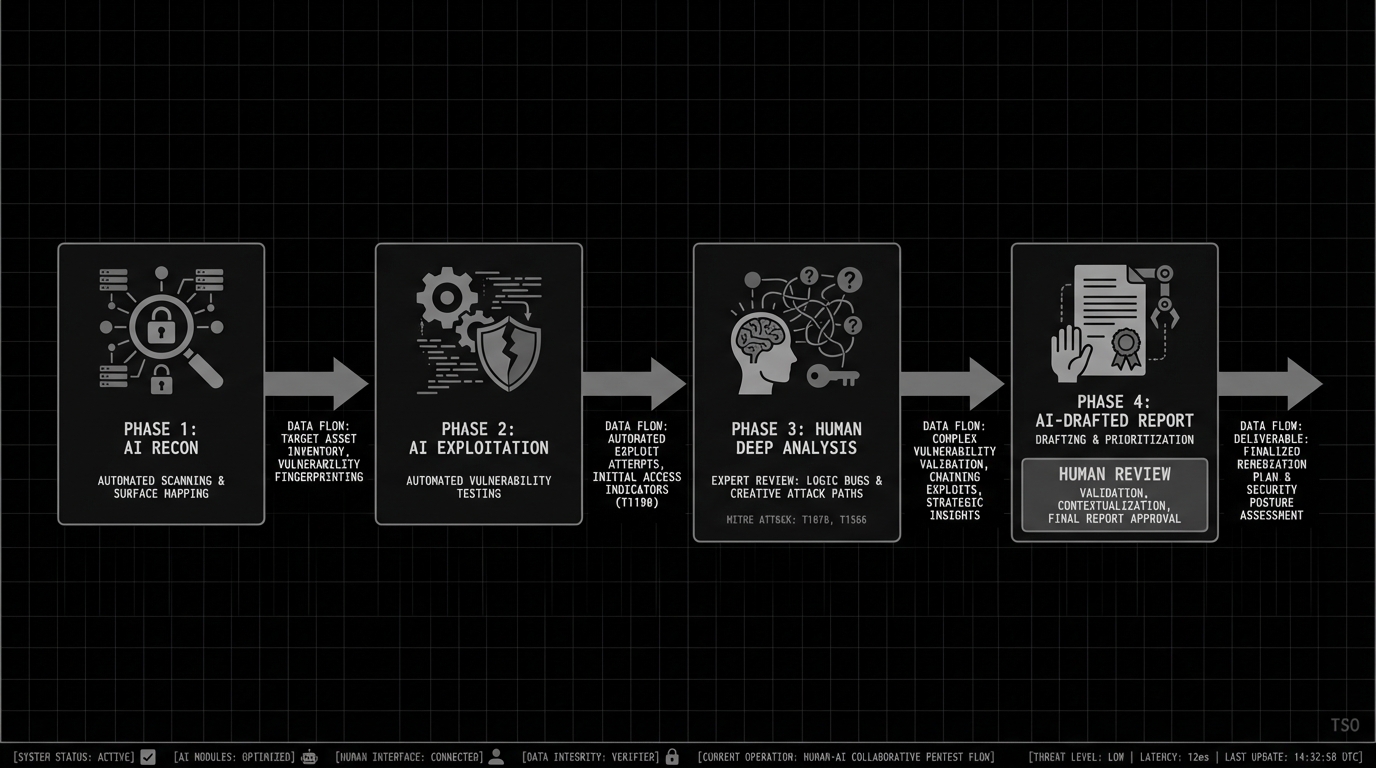
Full autonomy isn’t the right model, and honestly, it may never be for the work that matters most. What works is augmented testing: AI covers breadth and grunt work, humans bring the insight and creative thinking that actually finds the interesting stuff.
In practice, this looks like:
- AI handles recon and scanning. Automated surface mapping, enumeration, initial vuln detection across the full scope.
- AI attempts exploitation. Agents generate proof-of-concept payloads and validate attack paths for what they find.
- Humans take the interesting work. Business logic, chained exploits, novel attack vectors, adversarial thinking. This is where experience and intuition pay off, and where the real engagement value lies.
- AI drafts the report. Humans review it, add the context that only someone who understands the client’s environment can provide, and sign off.
A good pentester with these tools becomes significantly more dangerous. They cover more ground without sacrificing the depth and creativity that clients are actually paying for. The AI handles what used to be tedious; the human focuses on what used to be impossible to get to in the time budget.
Impact
Offensive teams
A team with these tools covers more ground. Coverage moves from periodic to continuous. Gartner projects 60% of large enterprises will be running continuous automated red teaming by 2026. Time to finding drops too: XBOW’s 28 minutes vs. 40 hours is an 80x improvement on certain task types. That’s not typical across the board, but it shows what’s possible against well-scoped targets.
There’s also a staffing angle. Junior pentesters with AI assistance can handle routine assessments, which frees senior staff for the engagements that actually need experience.
Defenders
The same capabilities are available to attackers. Less experienced threat actors can now run operations that used to require deep technical skill. The real shift isn’t new attack methods; it’s that existing methods are accessible to more people, running at machine speed.
Assume your external attack surface is already being probed by AI-assisted adversaries. Plan accordingly.
Market signal
The pentesting market is projected to hit $3.9 billion by 2029. AI-driven offensive security companies raised over $600 million in 2025. XBOW pulled in $75 million after the HackerOne results. Money follows capability, and there’s a lot of both right now.
What comes next
The attack pace is going to accelerate
This is worth saying plainly: as the tooling around these models matures, attacks will get faster and more impactful. We’re still in the early days of harness development. The frameworks for chaining LLM reasoning with exploit tools are improving month over month. Every improvement in agent orchestration, memory management, and tool integration makes autonomous attacks cheaper and faster to execute. The barrier to entry for sophisticated offensive operations is dropping, and it’s not going to stop dropping.
Organizations that are still running annual pentests and calling it good should be concerned. The attackers are already running continuous.
Small models, big models, or both?
One question we keep coming back to internally: will offensive testing converge on large frontier models running on serious hardware, or will we see a shift toward smaller, specialized models fine-tuned for specific tasks?
There’s a case for both. A small model trained specifically on web app exploitation might outperform a general purpose frontier model on that narrow task, and it runs on modest hardware. But the frontier models have the reasoning depth to handle novel situations and chain complex multi-step attacks. Our guess is that the most effective setups will use both: small specialized models for the well-understood tasks (recon, known vuln patterns, report generation) and larger models for the creative reasoning where you need genuine depth.
Privacy and data governance
Here’s the elephant in the room that not enough people are talking about. Pentesting involves access to sensitive systems, proprietary code, internal network topologies, credentials, and client data. If your AI pentesting agent is calling a cloud API, that data is leaving your environment.
Can regulated industries even use cloud-hosted models for this? Financial services, healthcare, defense contractors, companies subject to GDPR: the compliance questions are real. Some organizations will need to run everything on-prem. The good news is that capable open-weight models are catching up fast. We may reach a point where the privacy question answers itself, because running a competent model locally is just… normal. But we’re not there yet for the hardest tasks, and the gap between cloud and local capability still matters.
The near-term roadmap
Over the next couple of years, expect purpose-built agents for specific domains (cloud, mobile, IoT, ICS) and always-on pentesting integrated into CI/CD pipelines. Better memory architectures should let agents sustain multi-day engagements instead of losing context after a few hours.
Further out, by 2027-2029, multi-agent systems will start handling complete red team operations: initial access through lateral movement, persistence, and exfiltration. Defensive AI will start actively countering offensive AI. Compliance frameworks will probably start recognizing AI-powered continuous testing as a valid assessment method.
The long game is AI that discovers genuinely new vulnerability classes and systems that handle responsible disclosure end to end. But even then, we think the best results will come from human-AI teams. The human brings the adversarial mindset, the contextual understanding, the judgment calls. The AI brings speed, coverage, and tireless persistence. That combination is hard to beat.
Recommendations
If you’re evaluating AI pentesting tools, start by using them to extend your existing team. The tech is not ready for unsupervised runs on anything that matters. Every critical or high finding from an AI agent should get human eyes before you commit remediation resources.
The biggest win is CI/CD integration: catching regressions on every deployment before they reach production. But benchmark against your own environment, not a vendor demo. Performance varies a lot across app types and tech stacks.
And think about the attacker side. Your adversaries have access to these same capabilities. Reduce your attack surface, harden auth, and build depth into your defenses. If you wouldn’t trust an AI pentester to run unsupervised against your systems, remember that an AI-assisted attacker doesn’t need your permission.
References
- From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code – Google Project Zero
- XBOW: The Road to Top 1 – XBOW
- PentestAgent: Incorporating LLM Agents to Automated Penetration Testing – ACM AsiaCCS 2025
- Automated Penetration Testing with LLM Agents and Classical Planning – arXiv
- What Makes a Good LLM Agent for Real-world Penetration Testing? – arXiv
- CurriculumPT: LLM-Based Multi-Agent Autonomous Penetration Testing – Applied Sciences
- The 2026 Ultimate Guide to AI Penetration Testing – Penligent
- The New Offense: How AI Agents Are Rewriting Offensive Security – Resilient Cyber
- Understanding the Future of Offensive AI in Cybersecurity – IBM X-Force
- Zen-AI-Pentest: Open-source AI-powered Penetration Testing Framework – Help Net Security